Competition : https://www.kaggle.com/c/nyc-taxi-trip-duration/overview
Code : https://www.kaggle.com/gaborfodor/from-eda-to-the-top-lb-0-367
Description

Data Field
- id - a unique identifier for each trip
- vendor_id - a code indicating the provider associated with the trip record
- pickup_datetime - date and time when the meter was engaged
- dropoff_datetime - date and time when the meter was disengaged
- passenger_count - the number of passengers in the vehicle (driver entered value)
- pickup_longitude - the longitude where the meter was engaged
- pickup_latitude - the latitude where the meter was engaged
- dropoff_longitude - the longitude where the meter was disengaged
- dropoff_latitude - the latitude where the meter was disengaged
- store_and_fwd_flag - 공급업체에 보내기 전에 차량 메모리에 여행 기록이 보관되었는지 여부
- Y=store and forward; N=not a store and forward trip
- trip_duration - duration of the trip in seconds
Introduction
process
- Explore the dataset
- Extract 59 useful features
- Create simple 80-20 train - validation set
- Train XGBregressor
- Analyze Feature Importance
- Score test set and submit
- Check XGB parameter search result for further improvements
%matplotlib inline
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from datetime import timedelta
import datetime as dt
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [16, 10]
import seaborn as sns
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.cluster import MiniBatchKMeans
import warnings
warnings.filterwarnings('ignore')1. Data Understanding
np.random.seed(1987)
N = 100000 # number of sample rows in plots
t0 = dt.datetime.now()
train = pd.read_csv('../input/nyc-taxi-trip-duration/train.csv')
test = pd.read_csv('../input/nyc-taxi-trip-duration/test.csv')
sample_submission = pd.read_csv('../input/nyc-taxi-trip-duration/sample_submission.csv')print('We have {} training rows and {} test rows.'.format(train.shape[0], test.shape[0]))
print('We have {} training columns and {} test columns.'.format(train.shape[1], test.shape[1]))
train.head(2)
>>>
We have 1458644 training rows and 625134 test rows.
We have 11 training columns and 9 test columns.print('Id is unique.') if train.id.nunique() == train.shape[0] else print('oops')
print('Train and test sets are distinct.') if len(np.intersect1d(train.id.values, test.id.values))== 0 else print('oops')
print('We do not need to worry about missing values.') if train.count().min() == train.shape[0] and test.count().min() == test.shape[0] else print('oops')
print('The store_and_fwd_flag has only two values {}.'.format(str(set(train.store_and_fwd_flag.unique()) | set(test.store_and_fwd_flag.unique()))))
>>>
Id is unique.
Train and test sets are distinct.
We do not need to worry about missing values.
The store_and_fwd_flag has only two values {'Y', 'N'}.Data Preprocessing
train['pickup_datetime'] = pd.to_datetime(train.pickup_datetime)
test['pickup_datetime'] = pd.to_datetime(test.pickup_datetime)
train.loc[:, 'pickup_date'] = train['pickup_datetime'].dt.date
test.loc[:, 'pickup_date'] = test['pickup_datetime'].dt.date
train['dropoff_datetime'] = pd.to_datetime(train.dropoff_datetime)
train['store_and_fwd_flag'] = 1 * (train.store_and_fwd_flag.values == 'Y')
test['store_and_fwd_flag'] = 1 * (test.store_and_fwd_flag.values == 'Y')
train['check_trip_duration'] = (train['dropoff_datetime'] - train['pickup_datetime']).map(lambda x: x.total_seconds())
duration_difference = train[np.abs(train['check_trip_duration'].values - train['trip_duration'].values) > 1]
print('Trip_duration and datetimes are ok.') if len(duration_difference[['pickup_datetime', 'dropoff_datetime', 'trip_duration', 'check_trip_duration']]) == 0 else print('Ooops.')
>>>
Trip_duration and datetimes are ok.Target Variable
train['trip_duration'].max() // 3600
>>>
979trip duration이 최대 979까지 있는것을 확인할 수 있다. 그렇기 때문에 평가지표로 RMSLE를 사용하거나, log 변환 후 RMSE를 사용한다.
train['log_trip_duration'] = np.log(train['trip_duration'].values + 1)
plt.hist(train['log_trip_duration'].values, bins=100)
plt.xlabel('log(trip_duration)')
plt.ylabel('number of train records')
plt.show()Validation Strategy
학습데이터와 검증 데이터가 어떤식으로 되어있는지를 확인하면 validation stratigy를 결정하고 feature engineering에 관한 아이디어를 주는데 도움이 될 것이다.
plt.plot(train.groupby('pickup_date').count()[['id']], 'o-', label='train')
plt.plot(test.groupby('pickup_date').count()[['id']], 'o-', label='test')
plt.title('Train and test period complete overlap.')
plt.legend(loc=0)
plt.ylabel('number of records')
plt.show()city_long_border = (-74.03, -73.75)
city_lat_border = (40.63, 40.85)
fig, ax = plt.subplots(ncols=2, sharex=True, sharey=True)
ax[0].scatter(train['pickup_longitude'].values[:N], train['pickup_latitude'].values[:N],
color='blue', s=1, label='train', alpha=0.1)
ax[1].scatter(test['pickup_longitude'].values[:N], test['pickup_latitude'].values[:N],
color='green', s=1, label='test', alpha=0.1)
fig.suptitle('Train and test area complete overlap.')
ax[0].legend(loc=0)
ax[0].set_ylabel('latitude')
ax[0].set_xlabel('longitude')
ax[1].set_xlabel('longitude')
ax[1].legend(loc=0)
plt.ylim(city_lat_border)
plt.xlim(city_long_border)
plt.show()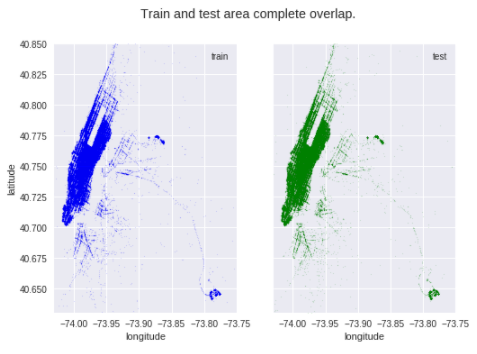
학습 데이터와 검증 데이터가 random하게 나눠져 있는 것으로 보인다. 이는 전체 데이터셋에 대해 unsupervised learning과 feature extraction을 사용할것을 허용한다.
2. Feature Extraction
PCA
위도와 경도를 변환하기 위해 PCA 사용. 이번에는 2D -> 2D 이기 때문에 차원축소는 하지 않는다. 이러한 변환은 decision tree split에 도움을 줄 수 있다.
coords = np.vstack((train[['pickup_latitude', 'pickup_longitude']].values,
train[['dropoff_latitude', 'dropoff_longitude']].values,
test[['pickup_latitude', 'pickup_longitude']].values,
test[['dropoff_latitude', 'dropoff_longitude']].values))
pca = PCA().fit(coords)
train['pickup_pca0'] = pca.transform(train[['pickup_latitude', 'pickup_longitude']])[:, 0]
train['pickup_pca1'] = pca.transform(train[['pickup_latitude', 'pickup_longitude']])[:, 1]
train['dropoff_pca0'] = pca.transform(train[['dropoff_latitude', 'dropoff_longitude']])[:, 0]
train['dropoff_pca1'] = pca.transform(train[['dropoff_latitude', 'dropoff_longitude']])[:, 1]
test['pickup_pca0'] = pca.transform(test[['pickup_latitude', 'pickup_longitude']])[:, 0]
test['pickup_pca1'] = pca.transform(test[['pickup_latitude', 'pickup_longitude']])[:, 1]
test['dropoff_pca0'] = pca.transform(test[['dropoff_latitude', 'dropoff_longitude']])[:, 0]
test['dropoff_pca1'] = pca.transform(test[['dropoff_latitude', 'dropoff_longitude']])[:, 1]fig, ax = plt.subplots(ncols=2)
ax[0].scatter(train['pickup_longitude'].values[:N], train['pickup_latitude'].values[:N],
color='blue', s=1, alpha=0.1)
ax[1].scatter(train['pickup_pca0'].values[:N], train['pickup_pca1'].values[:N],
color='green', s=1, alpha=0.1)
fig.suptitle('Pickup lat long coords and PCA transformed coords.')
ax[0].set_ylabel('latitude')
ax[0].set_xlabel('longitude')
ax[1].set_xlabel('pca0')
ax[1].set_ylabel('pca1')
ax[0].set_xlim(city_long_border)
ax[0].set_ylim(city_lat_border)
pca_borders = pca.transform([[x, y] for x in city_lat_border for y in city_long_border])
ax[1].set_xlim(pca_borders[:, 0].min(), pca_borders[:, 0].max())
ax[1].set_ylim(pca_borders[:, 1].min(), pca_borders[:, 1].max())
plt.show()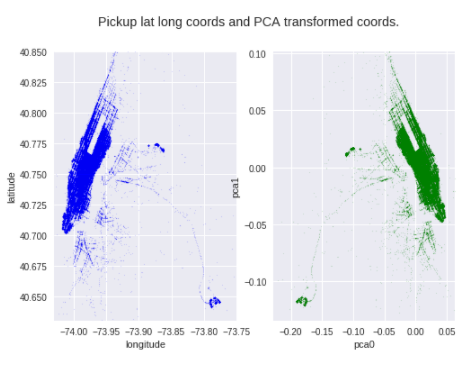
Distance
pickup과 dropout간의 거리 계산. haversine 공식, manhattan distance를 이용한다.(geopy 라이브러리에는 vincenty() or great_circle()등이 있다.)
- haversine
- Manhattan

def haversine_array(lat1, lng1, lat2, lng2):
lat1, lng1, lat2, lng2 = map(np.radians, (lat1, lng1, lat2, lng2))
AVG_EARTH_RADIUS = 6371 # in km
lat = lat2 - lat1
lng = lng2 - lng1
d = np.sin(lat * 0.5) ** 2 + np.cos(lat1) * np.cos(lat2) * np.sin(lng * 0.5) ** 2
h = 2 * AVG_EARTH_RADIUS * np.arcsin(np.sqrt(d))
return h
def dummy_manhattan_distance(lat1, lng1, lat2, lng2):
a = haversine_array(lat1, lng1, lat1, lng2)
b = haversine_array(lat1, lng1, lat2, lng1)
return a + b
def bearing_array(lat1, lng1, lat2, lng2):
AVG_EARTH_RADIUS = 6371 # in km
lng_delta_rad = np.radians(lng2 - lng1)
lat1, lng1, lat2, lng2 = map(np.radians, (lat1, lng1, lat2, lng2))
y = np.sin(lng_delta_rad) * np.cos(lat2)
x = np.cos(lat1) * np.sin(lat2) - np.sin(lat1) * np.cos(lat2) * np.cos(lng_delta_rad)
return np.degrees(np.arctan2(y, x))train.loc[:, 'distance_haversine'] = haversine_array(train['pickup_latitude'].values,
train['pickup_longitude'].values, train['dropoff_latitude'].values, train['dropoff_longitude'].values)
train.loc[:, 'distance_dummy_manhattan'] = dummy_manhattan_distance(train['pickup_latitude'].values,
train['pickup_longitude'].values, train['dropoff_latitude'].values, train['dropoff_longitude'].values)
train.loc[:, 'direction'] = bearing_array(train['pickup_latitude'].values,
train['pickup_longitude'].values, train['dropoff_latitude'].values, train['dropoff_longitude'].values)
train.loc[:, 'pca_manhattan'] = np.abs(train['dropoff_pca1'] - train['pickup_pca1']) +
np.abs(train['dropoff_pca0'] - train['pickup_pca0'])
test.loc[:, 'distance_haversine'] = haversine_array(test['pickup_latitude'].values,
test['pickup_longitude'].values, test['dropoff_latitude'].values, test['dropoff_longitude'].values)
test.loc[:, 'distance_dummy_manhattan'] = dummy_manhattan_distance(test['pickup_latitude'].values,
test['pickup_longitude'].values, test['dropoff_latitude'].values, test['dropoff_longitude'].values)
test.loc[:, 'direction'] = bearing_array(test['pickup_latitude'].values,
test['pickup_longitude'].values, test['dropoff_latitude'].values, test['dropoff_longitude'].values)
test.loc[:, 'pca_manhattan'] = np.abs(test['dropoff_pca1'] - test['pickup_pca1']) +
np.abs(test['dropoff_pca0'] - test['pickup_pca0'])
train.loc[:, 'center_latitude'] = (train['pickup_latitude'].values +
train['dropoff_latitude'].values) / 2
train.loc[:, 'center_longitude'] = (train['pickup_longitude'].values +
train['dropoff_longitude'].values) / 2
test.loc[:, 'center_latitude'] = (test['pickup_latitude'].values +
test['dropoff_latitude'].values) / 2
test.loc[:, 'center_longitude'] = (test['pickup_longitude'].values +
test['dropoff_longitude'].values) / 2Datetime Features
train.loc[:, 'pickup_weekday'] = train['pickup_datetime'].dt.weekday
train.loc[:, 'pickup_hour_weekofyear'] = train['pickup_datetime'].dt.weekofyear
train.loc[:, 'pickup_hour'] = train['pickup_datetime'].dt.hour
train.loc[:, 'pickup_minute'] = train['pickup_datetime'].dt.minute
train.loc[:, 'pickup_dt'] = (train['pickup_datetime'] - train['pickup_datetime'].min()).dt.total_seconds()
train.loc[:, 'pickup_week_hour'] = train['pickup_weekday'] * 24 + train['pickup_hour']
test.loc[:, 'pickup_weekday'] = test['pickup_datetime'].dt.weekday
test.loc[:, 'pickup_hour_weekofyear'] = test['pickup_datetime'].dt.weekofyear
test.loc[:, 'pickup_hour'] = test['pickup_datetime'].dt.hour
test.loc[:, 'pickup_minute'] = test['pickup_datetime'].dt.minute
test.loc[:, 'pickup_dt'] = (test['pickup_datetime'] - train['pickup_datetime'].min()).dt.total_seconds()
test.loc[:, 'pickup_week_hour'] = test['pickup_weekday'] * 24 + test['pickup_hour']Speed
train.loc[:, 'avg_speed_h'] = 1000 * train['distance_haversine'] / train['trip_duration']
train.loc[:, 'avg_speed_m'] = 1000 * train['distance_dummy_manhattan'] / train['trip_duration']
fig, ax = plt.subplots(ncols=3, sharey=True)
ax[0].plot(train.groupby('pickup_hour').mean()['avg_speed_h'], 'bo-', lw=2, alpha=0.7)
ax[1].plot(train.groupby('pickup_weekday').mean()['avg_speed_h'], 'go-', lw=2, alpha=0.7)
ax[2].plot(train.groupby('pickup_week_hour').mean()['avg_speed_h'], 'ro-', lw=2, alpha=0.7)
ax[0].set_xlabel('hour')
ax[1].set_xlabel('weekday')
ax[2].set_xlabel('weekhour')
ax[0].set_ylabel('average speed')
fig.suptitle('Rush hour average traffic speed')
plt.show()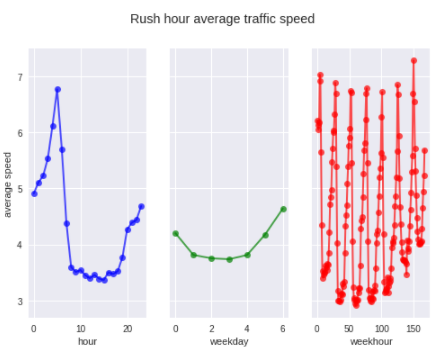
Average Speed for regions
train.loc[:, 'pickup_lat_bin'] = np.round(train['pickup_latitude'], 3)
train.loc[:, 'pickup_long_bin'] = np.round(train['pickup_longitude'], 3)
# Average speed for regions
gby_cols = ['pickup_lat_bin', 'pickup_long_bin']
coord_speed = train.groupby(gby_cols).mean()[['avg_speed_h']].reset_index()
coord_count = train.groupby(gby_cols).count()[['id']].reset_index()
coord_stats = pd.merge(coord_speed, coord_count, on=gby_cols)
coord_stats = coord_stats[coord_stats['id'] > 100]
fig, ax = plt.subplots(ncols=1, nrows=1)
ax.scatter(train.pickup_longitude.values[:N], train.pickup_latitude.values[:N],
color='black', s=1, alpha=0.5)
ax.scatter(coord_stats.pickup_long_bin.values, coord_stats.pickup_lat_bin.values,
c=coord_stats.avg_speed_h.values,
cmap='RdYlGn', s=20, alpha=0.5, vmin=1, vmax=8)
ax.set_xlim(city_long_border)
ax.set_ylim(city_lat_border)
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
plt.title('Average speed')
plt.show()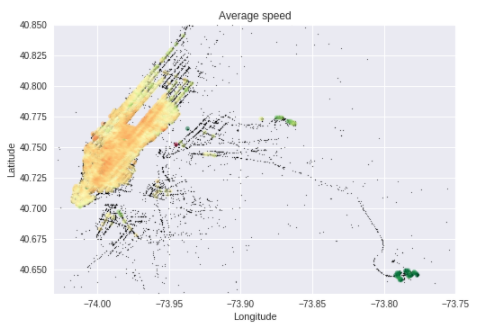
train.loc[:, 'pickup_lat_bin'] = np.round(train['pickup_latitude'], 2)
train.loc[:, 'pickup_long_bin'] = np.round(train['pickup_longitude'], 2)
train.loc[:, 'center_lat_bin'] = np.round(train['center_latitude'], 2)
train.loc[:, 'center_long_bin'] = np.round(train['center_longitude'], 2)
train.loc[:, 'pickup_dt_bin'] = (train['pickup_dt'] // (3 * 3600))
test.loc[:, 'pickup_lat_bin'] = np.round(test['pickup_latitude'], 2)
test.loc[:, 'pickup_long_bin'] = np.round(test['pickup_longitude'], 2)
test.loc[:, 'center_lat_bin'] = np.round(test['center_latitude'], 2)
test.loc[:, 'center_long_bin'] = np.round(test['center_longitude'], 2)
test.loc[:, 'pickup_dt_bin'] = (test['pickup_dt'] // (3 * 3600))Clustering
sample_ind = np.random.permutation(len(coords))[:500000]
kmeans = MiniBatchKMeans(n_clusters=100, batch_size=10000).fit(coords[sample_ind])'''
coords = np.vstack((train[['pickup_latitude', 'pickup_longitude']].values,
train[['dropoff_latitude', 'dropoff_longitude']].values,
test[['pickup_latitude', 'pickup_longitude']].values,
test[['dropoff_latitude', 'dropoff_longitude']].values))
'''train.loc[:, 'pickup_cluster'] = kmeans.predict(train[['pickup_latitude', 'pickup_longitude']])
train.loc[:, 'dropoff_cluster'] = kmeans.predict(train[['dropoff_latitude', 'dropoff_longitude']])
test.loc[:, 'pickup_cluster'] = kmeans.predict(test[['pickup_latitude', 'pickup_longitude']])
test.loc[:, 'dropoff_cluster'] = kmeans.predict(test[['dropoff_latitude', 'dropoff_longitude']])fig, ax = plt.subplots(ncols=1, nrows=1)
ax.scatter(train.pickup_longitude.values[:N], train.pickup_latitude.values[:N], s=10, lw=0,
c=train.pickup_cluster[:N].values, cmap='tab20', alpha=0.2)
ax.set_xlim(city_long_border)
ax.set_ylim(city_lat_border)
ax.set_xlabel('Longitude')
ax.set_ylabel('Latitude')
plt.show()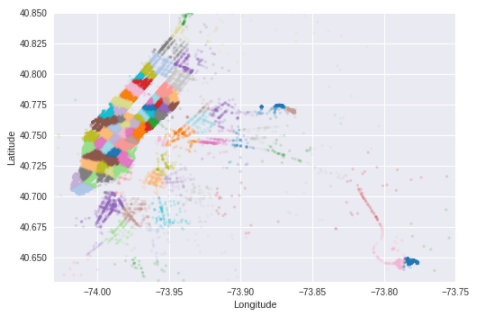
Temporal and geospatial aggregation
- average traffic speed 변수를 몇개 추가한다.
for gby_col in ['pickup_hour', 'pickup_date', 'pickup_dt_bin',
'pickup_week_hour', 'pickup_cluster', 'dropoff_cluster']:
gby = train.groupby(gby_col).mean()[['avg_speed_h', 'avg_speed_m', 'log_trip_duration']]
gby.columns = ['%s_gby_%s' % (col, gby_col) for col in gby.columns]
train = pd.merge(train, gby, how='left', left_on=gby_col, right_index=True)
test = pd.merge(test, gby, how='left', left_on=gby_col, right_index=True)
for gby_cols in [['center_lat_bin', 'center_long_bin'],
['pickup_hour', 'center_lat_bin', 'center_long_bin'],
['pickup_hour', 'pickup_cluster'], ['pickup_hour', 'dropoff_cluster'],
['pickup_cluster', 'dropoff_cluster']]:
coord_speed = train.groupby(gby_cols).mean()[['avg_speed_h']].reset_index()
coord_count = train.groupby(gby_cols).count()[['id']].reset_index()
coord_stats = pd.merge(coord_speed, coord_count, on=gby_cols)
coord_stats = coord_stats[coord_stats['id'] > 100]
coord_stats.columns = gby_cols + ['avg_speed_h_%s' % '_'.join(gby_cols), 'cnt_%s' % '_'.join(gby_cols)]
train = pd.merge(train, coord_stats, how='left', on=gby_cols)
test = pd.merge(test, coord_stats, how='left', on=gby_cols)- ['pickup_hour', 'pickup_date', 'pickup_dt_bin', 'pickup_week_hour', 'pickup_cluster', 'dropoff_cluster'] 에 대해 각각 groupby를 진행한 후 'avg_speed_h', 'avg_speed_m', 'log_trip_duration' 값들의 평균값을 구해 새로운 변수를 생성한다.
- [['center_lat_bin', 'center_long_bin'],['pickup_hour', 'center_lat_bin', 'center_long_bin'],
['pickup_hour', 'pickup_cluster'], ['pickup_hour', 'dropoff_cluster'],['pickup_cluster', 'dropoff_cluster']] 에 대해 각각 그룹화를 진행한 후, 'avg_speed_h'를 구하여 새로운 컬럼 생성 - 두 과정은 train 데이터로 진행한 후 이 값들을 test 데이터에 같이 생성함.
group_freq = '60min'
df_all = pd.concat((train, test))[['id', 'pickup_datetime', 'pickup_cluster', 'dropoff_cluster']]
train.loc[:, 'pickup_datetime_group'] = train['pickup_datetime'].dt.round(group_freq)
test.loc[:, 'pickup_datetime_group'] = test['pickup_datetime'].dt.round(group_freq)
# Count trips over 60min
df_counts = df_all.set_index('pickup_datetime')[['id']].sort_index()
df_counts['count_60min'] = df_counts.isnull().rolling(group_freq).count()['id']
train = train.merge(df_counts, on='id', how='left')
test = test.merge(df_counts, on='id', how='left')4. 60분당 건수 계산
# Count how many trips are going to each cluster over time
dropoff_counts = df_all \
.set_index('pickup_datetime') \
.groupby([pd.TimeGrouper(group_freq), 'dropoff_cluster']) \
.agg({'id': 'count'}) \
.reset_index().set_index('pickup_datetime') \
.groupby('dropoff_cluster').rolling('240min').mean() \
.drop('dropoff_cluster', axis=1) \
.reset_index().set_index('pickup_datetime').shift(freq='-120min').reset_index() \
.rename(columns={'pickup_datetime': 'pickup_datetime_group', 'id': 'dropoff_cluster_count'})
train['dropoff_cluster_count'] = train[['pickup_datetime_group', 'dropoff_cluster']].merge(dropoff_counts, on=['pickup_datetime_group', 'dropoff_cluster'], how='left')['dropoff_cluster_count'].fillna(0)
test['dropoff_cluster_count'] = test[['pickup_datetime_group', 'dropoff_cluster']].merge(dropoff_counts, on=['pickup_datetime_group', 'dropoff_cluster'], how='left')['dropoff_cluster_count'].fillna(0)
# Count how many trips are going from each cluster over time
df_all = pd.concat((train, test))[['id', 'pickup_datetime', 'pickup_cluster', 'dropoff_cluster']]
pickup_counts = df_all \
.set_index('pickup_datetime') \
.groupby([pd.TimeGrouper(group_freq), 'pickup_cluster']) \
.agg({'id': 'count'}) \
.reset_index().set_index('pickup_datetime') \
.groupby('pickup_cluster').rolling('240min').mean() \
.drop('pickup_cluster', axis=1) \
.reset_index().set_index('pickup_datetime').shift(freq='-120min').reset_index() \
.rename(columns={'pickup_datetime': 'pickup_datetime_group', 'id': 'pickup_cluster_count'})
train['pickup_cluster_count'] = train[['pickup_datetime_group', 'pickup_cluster']].merge(pickup_counts, on=['pickup_datetime_group', 'pickup_cluster'], how='left')['pickup_cluster_count'].fillna(0)
test['pickup_cluster_count'] = test[['pickup_datetime_group', 'pickup_cluster']].merge(pickup_counts, on=['pickup_datetime_group', 'pickup_cluster'], how='left')['pickup_cluster_count'].fillna(0)5. 각 cluster를 기준으로 trip 수 count
- OSRM Features
pickup과 dropoff 사이의 최단 경로를 구하기 위해 OSRM Data 사용
fr1 = pd.read_csv('../input/new-york-city-taxi-with-osrm/fastest_routes_train_part_1.csv',
usecols=['id', 'total_distance', 'total_travel_time', 'number_of_steps'])
fr2 = pd.read_csv('../input/new-york-city-taxi-with-osrm/fastest_routes_train_part_2.csv',
usecols=['id', 'total_distance', 'total_travel_time', 'number_of_steps'])
test_street_info = pd.read_csv('../input/new-york-city-taxi-with-osrm/fastest_routes_test.csv',
usecols=['id', 'total_distance', 'total_travel_time', 'number_of_steps'])
train_street_info = pd.concat((fr1, fr2))
train = train.merge(train_street_info, how='left', on='id')
test = test.merge(test_street_info, how='left', on='id')
train_street_info.head()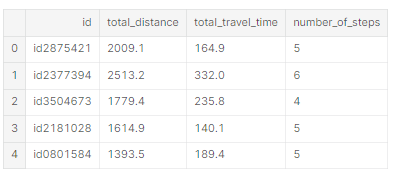
feature_names = list(train.columns)
print(np.setdiff1d(train.columns, test.columns))
do_not_use_for_training = ['id', 'log_trip_duration', 'pickup_datetime', 'dropoff_datetime',
'trip_duration', 'check_trip_duration',
'pickup_date', 'avg_speed_h', 'avg_speed_m',
'pickup_lat_bin', 'pickup_long_bin',
'center_lat_bin', 'center_long_bin',
'pickup_dt_bin', 'pickup_datetime_group']
feature_names = [f for f in train.columns if f not in do_not_use_for_training]
# print(feature_names)
print('We have %i features.' % len(feature_names))
train[feature_names].count()
y = np.log(train['trip_duration'].values + 1)
>>>
We have 59 features.Feature check before modeling
일반적으로 캐글은 train과 test 데이터가 iid이다. 만약 두 데이터간에 큰 차이가 있다면 feature extraction pipeline에 큰 오류가 있을 것이다.
feature_stats = pd.DataFrame({'feature': feature_names})
feature_stats.loc[:, 'train_mean'] = np.nanmean(train[feature_names].values, axis=0).round(4)
feature_stats.loc[:, 'test_mean'] = np.nanmean(test[feature_names].values, axis=0).round(4)
feature_stats.loc[:, 'train_std'] = np.nanstd(train[feature_names].values, axis=0).round(4)
feature_stats.loc[:, 'test_std'] = np.nanstd(test[feature_names].values, axis=0).round(4)
feature_stats.loc[:, 'train_nan'] = np.mean(np.isnan(train[feature_names].values), axis=0).round(3)
feature_stats.loc[:, 'test_nan'] = np.mean(np.isnan(test[feature_names].values), axis=0).round(3)
feature_stats.loc[:, 'train_test_mean_diff'] = np.abs(feature_stats['train_mean'] - feature_stats['test_mean']) / np.abs(feature_stats['train_std'] + feature_stats['test_std']) * 2
feature_stats.loc[:, 'train_test_nan_diff'] = np.abs(feature_stats['train_nan'] - feature_stats['test_nan'])
feature_stats = feature_stats.sort_values(by='train_test_mean_diff')
feature_stats[['feature', 'train_test_mean_diff']].tail()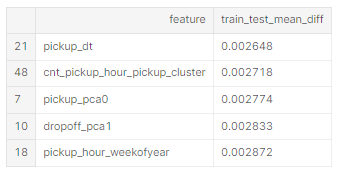
feature_stats = feature_stats.sort_values(by='train_test_nan_diff')
feature_stats[['feature', 'train_nan', 'test_nan', 'train_test_nan_diff']].tail()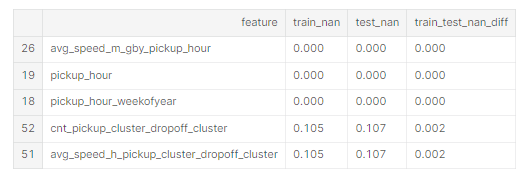
상위 평균 차이도 표준 편차의 1% 미만입니다. 몇 가지 결측값이 있지만 결측률은 동일합니다. 다행히 xgboost는 누락된 값을 처리할 수 있습니다.
3. Modeling
Xtr, Xv, ytr, yv = train_test_split(train[feature_names].values, y, test_size=0.2, random_state=1987)
dtrain = xgb.DMatrix(Xtr, label=ytr)
dvalid = xgb.DMatrix(Xv, label=yv)
dtest = xgb.DMatrix(test[feature_names].values)
watchlist = [(dtrain, 'train'), (dvalid, 'valid')]
# Try different parameters! My favorite is random search :)
xgb_pars = {'min_child_weight': 50, 'eta': 0.3, 'colsample_bytree': 0.3, 'max_depth': 10,
'subsample': 0.8, 'lambda': 1., 'nthread': 4, 'booster' : 'gbtree', 'silent': 1,
'eval_metric': 'rmse', 'objective': 'reg:linear'}model = xgb.train(xgb_pars, dtrain, 60, watchlist, early_stopping_rounds=50,
maximize=False, verbose_eval=10)[0] train-rmse:4.22547 valid-rmse:4.22659
Multiple eval metrics have been passed: 'valid-rmse' will be used for early stopping.
Will train until valid-rmse hasn't improved in 50 rounds.
[10] train-rmse:0.40166 valid-rmse:0.416253
[20] train-rmse:0.370141 valid-rmse:0.390849
[30] train-rmse:0.360826 valid-rmse:0.387562
[40] train-rmse:0.355397 valid-rmse:0.38651
[50] train-rmse:0.351369 valid-rmse:0.385515
[59] train-rmse:0.348421 valid-rmse:0.385454print('Modeling RMSLE %.5f' % model.best_score)
t1 = dt.datetime.now()
print('Training time: %i seconds' % (t1 - t0).seconds)
>>>
Modeling RMSLE 0.38538
Training time: 272 secondsFeature importance analysis
XGBoost에서 제공하는 feature importance score는 점수가 높을수록 해당 기능이 더 많은 트리 분할에 사용됨을 의미한다. 여기서는 backward feature elimation round를 시도했는데, 각 feature가 없이 학습을 진행함으로써 어떠한 feature를 제거하지 말아야 하는가를 알 수 있다. 시간이 오래걸려 따로 진행한 값 이용.
rmse_wo_feature = [0.39224, 0.38816, 0.38726, 0.38780, 0.38773, 0.38792, 0.38753, 0.38745, 0.38710, 0.38767, 0.38738, 0.38750, 0.38678, 0.39359, 0.38672, 0.38794, 0.38694, 0.38750, 0.38742, 0.38673, 0.38754, 0.38705, 0.38736, 0.38741, 0.38764, 0.38730, 0.38676, 0.38696, 0.38750, 0.38705, 0.38746, 0.38727, 0.38750, 0.38771, 0.38747, 0.38907, 0.38719, 0.38756, 0.38701, 0.38734, 0.38782, 0.38673, 0.38797, 0.38720, 0.38709, 0.38704, 0.38809, 0.38768, 0.38798, 0.38849, 0.38690, 0.38753, 0.38721, 0.38807, 0.38830, 0.38750, np.nan, np.nan, np.nan]
feature_importance_dict = model.get_fscore()
fs = ['f%i' % i for i in range(len(feature_names))]
f1 = pd.DataFrame({'f': list(feature_importance_dict.keys()),
'importance': list(feature_importance_dict.values())})
f2 = pd.DataFrame({'f': fs, 'feature_name': feature_names, 'rmse_wo_feature': rmse_wo_feature})
feature_importance = pd.merge(f1, f2, how='right', on='f')
feature_importance = feature_importance.fillna(0)
feature_importance[['feature_name', 'importance', 'rmse_wo_feature']].sort_values(by='importance', ascending=False)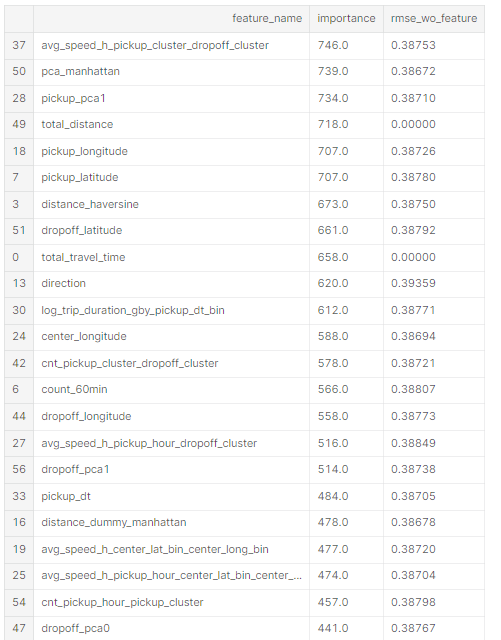
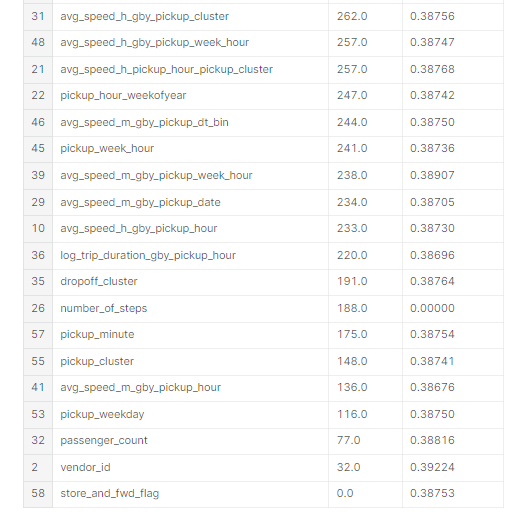
- high feature importance score를 가진 location related feature가 많았으나, 하나를 제거해도 에러는 증가하지 않는다.
- vendor_id는 2번째로 낮은 importance를 가지고 있지만, 제외시 에러값이 크게 증가한다.
- direction은 상관관계가 있는 feature가 별로 없고, 제외시 에러값이 크게 증가한다.
- 제외해도 모델에 크게 영향을 주지 않는 feature가 많이 있다.
feature_importance = feature_importance.sort_values(by='rmse_wo_feature', ascending=False)
feature_importance = feature_importance[feature_importance['rmse_wo_feature'] > 0]
with sns.axes_style("whitegrid"):
fig, ax = plt.subplots(figsize=(10, 10))
ax.scatter(feature_importance['importance'].values, feature_importance['rmse_wo_feature'].values,
c=feature_importance['rmse_wo_feature'].values, s=500, cmap='RdYlGn_r', alpha=0.7)
for _, row in feature_importance.head(5).iterrows():
ax.text(row['importance'], row['rmse_wo_feature'], row['feature_name'],
verticalalignment='center', horizontalalignment='center')
ax.set_xlabel('xgb feature importance')
ax.set_ylabel('rmse without feature')
ax.set_ylim(np.min(feature_importance['rmse_wo_feature']) - 0.001,
np.max(feature_importance['rmse_wo_feature']) + 0.001)
plt.show()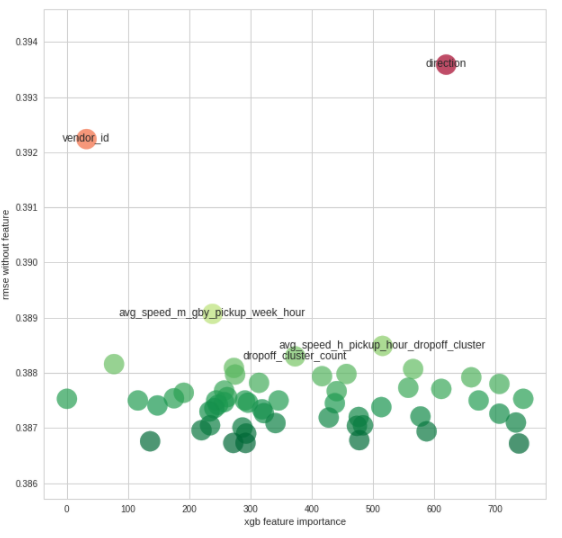
ypred = model.predict(dvalid)
fig,ax = plt.subplots(ncols=2)
ax[0].scatter(ypred, yv, s=0.1, alpha=0.1)
ax[0].set_xlabel('log(prediction)')
ax[0].set_ylabel('log(ground truth)')
ax[1].scatter(np.exp(ypred), np.exp(yv), s=0.1, alpha=0.1)
ax[1].set_xlabel('prediction')
ax[1].set_ylabel('ground truth')
plt.show()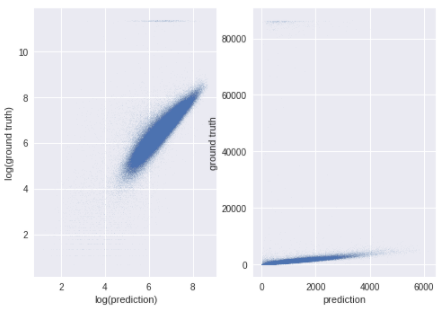
Appendix A. XGB Parameter Search Result
6가지 parameter에 대한 random search 진행
- min_child_weight
- eta
- colsample_bytree
- max_depth
- subsample
- lambda
FOREVER_COMPUTING_FLAG = False
xgb_pars = []
for MCW in [10, 20, 50, 75, 100]:
for ETA in [0.05, 0.1, 0.15]:
for CS in [0.3, 0.4, 0.5]:
for MD in [6, 8, 10, 12, 15]:
for SS in [0.5, 0.6, 0.7, 0.8, 0.9]:
for LAMBDA in [0.5, 1., 1.5, 2., 3.]:
xgb_pars.append({'min_child_weight': MCW, 'eta': ETA,
'colsample_bytree': CS, 'max_depth': MD,
'subsample': SS, 'lambda': LAMBDA,
'nthread': -1, 'booster' : 'gbtree', 'eval_metric': 'rmse',
'silent': 1, 'objective': 'reg:linear'})
while FOREVER_COMPUTING_FLAG:
xgb_par = np.random.choice(xgb_pars, 1)[0]
print(xgb_par)
model = xgb.train(xgb_par, dtrain, 2000, watchlist, early_stopping_rounds=50,
maximize=False, verbose_eval=100)
print('Modeling RMSLE %.5f' % model.best_score)Result
paropt = pd.DataFrame({'lambda':[1.5,1.0,1.0,1.5,1.5,1.0,1.5,1.0,1.5,2.0,0.5,1.0,0.5,1.5,1.5,0.5,1.0,1.5,0.5,2.0,1.0,2.0,2.0,1.5,1.5,2.0,1.5,2.0,1.5,0.5,1.0,1.0,2.0,1.5,1.0,1.0,0.5,2.0,1.0,0.5,0.5,2.0,1.0,1.0,0.5,0.5,1.5,0.5,1.5,2.0,2.0,2.0,2.0,0.5,1.5,1.0,1.5,2.0,2.0,0.5,1.5,1.0,0.5,1.0,1.5,2.0,1.0,1.0,2.0,2.0,1.0,0.5,0.5,1.0,1.5,2.0,0.5,1.0,1.5,1.0,1.0,1.5,1.5,1.5,0.5,1.5,1.0,1.5,2.0,2.0,2.0,1.0,2.0,0.5,2.0,0.5,1.5,0.5,2.0,0.5,1.0,1.5,1.5,1.5,2.0,0.5,0.5,1.0,2.0],
'eta':[.1,.1,.05,.05,.05,.15,.15,.1,.1,.05,.15,.15,.15,.1,.1,.1,.1,.05,.15,.05,.05,.05,.15,.15,.05,.05,.05,.05,.15,.15,.15,.15,.1,.05,.05,.1,.1,.1,.1,.1,.05,.15,.15,.15,.1,.1,.05,.05,.15,.15,.15,.1,.1,.05,.05,.05,.05,.05,.15,.1,.1,.15,.1,.1,.05,.15,.15,.15,.1,.05,.05,.05,.05,.15,.1,.1,.1,.1,.05,.05,.05,.15,.15,.1,.1,.1,.1,.05,.15,.15,.1,.1,.1,.05,.05,.1,.1,.1,.1,.1,.05,.15,.15,.15,.15,.05,.05,.15,.15],
'min_child_weight': [50,50,20,100,10,50,100,100,75,10,10,50,50,100,75,100,50,10,20,10,75,20,50,75,100,100,10,20,75,75,75,20,10,75,10,100,100,10,20,20,50,50,100,20,50,100,100,75,20,75,20,50,20,10,20,20,20,75,20,75,100,10,10,20,10,20,100,75,75,10,100,50,100,100,50,10,75,75,50,10,75,75,50,75,20,100,100,50,20,20,50,50,75,20,50,100,75,75,100,75,10,10,20,20,10,10,75,50,20],
'subsample':[.8,.9,.8,.6,.6,.6,.9,.6,.5,.9,.8,.9,.7,.5,.5,.9,.7,.7,.5,.8,.5,.9,.6,.6,.8,.8,.8,.7,.5,.5,.9,.9,.5,.6,.7,.8,.8,.6,.9,.7,.8,.6,.6,.9,.7,.7,.8,.6,.6,.5,.9,.8,.7,.6,.6,.6,.5,.9,.8,.5,.7,.6,.8,.6,.8,.8,.6,.7,.9,.5,.7,.5,.9,.7,.8,.9,.9,.7,.8,.5,.7,.8,.6,.8,.8,.5,.9,.5,.5,.7,.8,.6,.6,.8,.7,.6,.6,.6,.7,.7,.8,.6,.5,.9,.7,.6,.9,.5,.5],
'rmse': [.380,.380,.377,.378,.378,.386,.382,.382,.383,.374,.386,.381,.385,.383,.383,.379,.381,.376,.389,.375,.381,.374,.385,.385,.378,.377,.375,.376,.385,.386,.382,.384,.384,.379,.376,.380,.380,.382,.380,.382,.378,.385,.384,.383,.383,.383,.379,.381,.386,.387,.381,.380,.380,.377,.377,.377,.379,.376,.382,.385,.382,.386,.380,.382,.375,.383,.385,.384,.379,.378,.380,.381,.378,.384,.380,.377,.379,.383,.380,.380,.380,.383,.385,.381,.379,.386,.380,.383,.387,.383,.382,.384,.385,.377,.380,.383,.383,.383,.382,.382,.377,.386,.388,.382,.384,.379,.378,.387,.388]
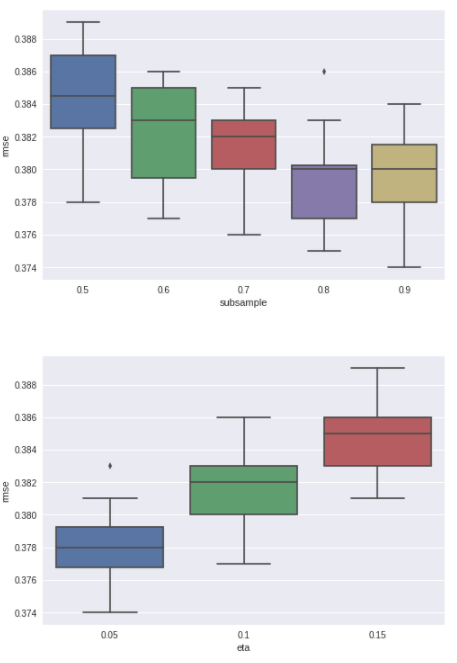
})for i, par in enumerate(['lambda', 'min_child_weight', 'subsample', 'eta']):
fig, ax = plt.subplots()
ax = sns.boxplot(x=par, y="rmse", data=paropt)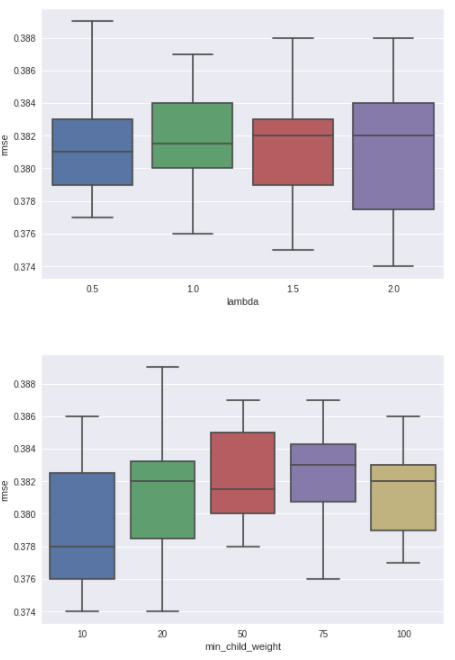
with sns.axes_style("whitegrid"):
fig, axs = plt.subplots(ncols=4, sharey=True, figsize=(12, 3))
for i, par in enumerate(['lambda', 'min_child_weight', 'subsample', 'eta']):
mean_rmse = paropt.groupby(par).mean()[['rmse']].reset_index()
axs[i].scatter(mean_rmse[par].values, mean_rmse['rmse'].values, c=mean_rmse['rmse'].values,
s=300, cmap='viridis_r', vmin=.377, vmax=.385, )
axs[i].set_xlabel(par)
axs[i].set_xticks(mean_rmse[par].values)
axs[i].set_ylim(paropt.rmse.min(), paropt.rmse.max())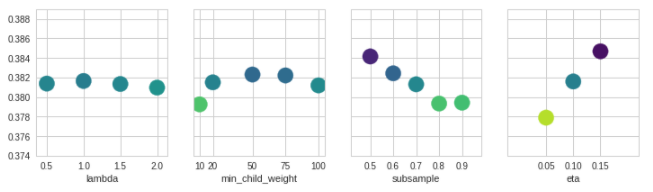
Appendix B. Cross Validation test
cv_lb = pd.DataFrame({'cv': [0.3604,0.36056,0.3614,0.3618,0.3623,0.3626,0.3646,0.3696,0.3702,0.3706,0.372,0.3738,0.37477,0.37691,0.3824,0.3868,0.3904],
'lb': [0.367,0.367,0.368,0.368,0.368,0.368,0.371,0.375,0.376,0.376,0.377,0.377,0.379,0.381,0.387,0.39,0.393]})
ax = sns.regplot(x="cv", y="lb", data=cv_lb, scatter_kws={'s': 200})
ax.set_xlabel('Local validation (RMSLE)')
ax.set_ylabel('Leaderboard (RMSLE)')
ax.set_title('Local validation and Leaderboard consistency')
print('CV - LB Diff: %.3f' % np.mean(cv_lb['lb'] - cv_lb['cv']))
>>>
CV - LB Diff: 0.005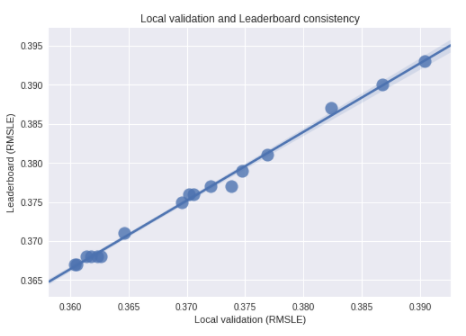
참고자료
https://www.baeldung.com/cs/haversine-formula
https://aigents.co/data-science-blog/publication/distance-metrics-for-machine-learning
'Kaggle' 카테고리의 다른 글
| House Prices - Advanced Regression Techniques 코드리뷰 2 (0) | 2022.01.26 |
|---|---|
| Bike Sharing Demand 코드리뷰 (0) | 2022.01.25 |
| House Prices - Advanced Regression Techniques 코드리뷰 (0) | 2022.01.17 |



댓글