본 글은 Stanford University CS231n 강의를 듣고 정리한 내용입니다.
- Fancier optimization
- Regularization
- Transfer Learning
Optimizer

W1와 W2를 optimizer하는 과정은 곧 오른쪽 그래프에서 가장 빨간 지점(가장 낮은 loss를 가지는 Weight)을 찾는 것이다.
위 사진같은 loss function의 경우 수평 방향으로는 loss가 매우 적게 줄어들지만, 수직방향으로는 변화에 매우 민감해진다.
수평 방향으로는 매우 느리게 진행되며, 수직 방향으로는 불안정(zigzag)하게 진행된다.
실제 모델은 수백만, 수천만개의 파라미터를 가지고 있고, 이는 수백 수천만개의 방향이 있음을 의미한다. 이 때 가장 큰 값과 작은 값의 비율이 안좋을 경우, SGD는 잘 작동하지 못한다. high dimension에서는 이 ratio가 클 확률이 높기 때문에 이는 high dimension에서는 문제가 된다.
gradient가 0인 지점에서 gradient descent는 갇히게 된다.
Local Minima와 Saddle Point의 차이점은 Local Minima는 지역적 최소값을 의미하고 Saddle Point는 gradient는 0이지만 계속 감수하는 함수에서의 지점을 의미한다. Saddle Point 근처에서의 경우 Gradient가 매우 작기 때문에 학습 과정이 상당히 오래 걸리게 된다.
mini batch를 이용해 gradient에 대한 true information이 아닌 noisy estimate를 얻음
velocity를 정의하고, gradient estimate값을 더해준다. 그런다음 gradient(dx) 방향으로 나아가지 않고 velocity(vs) 방향으로 나아간다. Rho값은 friction을 나타내는데, 일반적으로 0.9나 0.99를 많이 사용한다. friction에 의하여 속도를 감소시키고 gradient를 더해준다.
local minima 나 saddle point 근처에서 기울기는 0이 되지만 내려오던 속도가 있기 때문에 그 지점에 멈추지 않고 계속 진행하게 된다.
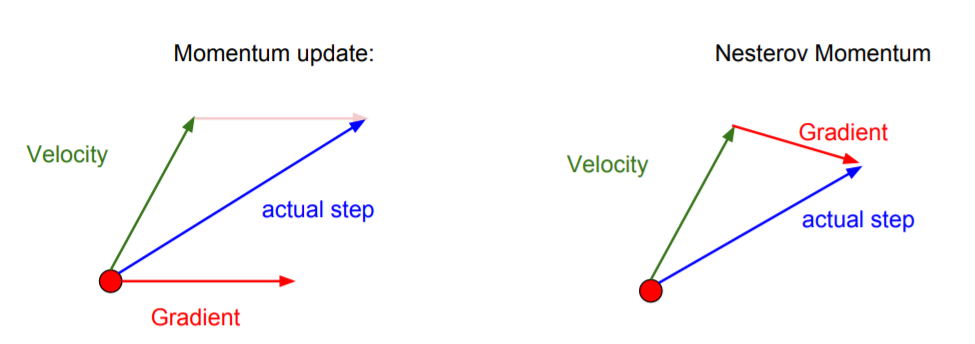
momentum update의 경우 원점에서 Velocity와 Gradient를 구하고, 이를 각각 더하여 진행하지만, Nesterov Momentum의 경우는 Velocity만큼 이동한 후 그 지점에서 Gradient를 구하여 이동하게 된다.
Nesterov Momentum
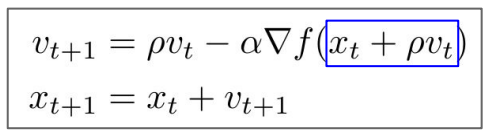
기존의 point가 아닌 multiple point(이전에 진행한 velocity와 Gradient)에서 다시 velocity를 계산한다.
일반적으로 loss와 gradient를 같은 지점에서 계산하고 싶어하나, Nesterov는 이와같은 방식이 불가능하여 약간 성가시다.
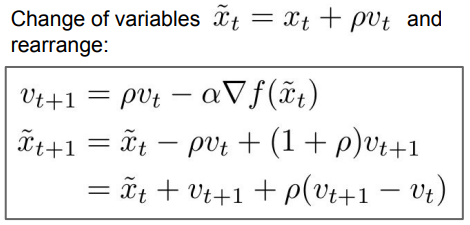
x_t + pv_t를 하나의 변수로 바꿔주고, 약간의 reshuffle을 해주게 되면 항상 loss과 gradient를 같은 지점에서 계산할 수 있다.

rho와 velocity를 이용해 새로운 velocity를 구해주는 부분까지는 같으나, 가장 아랫줄을 보게 되면 현재 지점에 현재 속도와 현재 속도와 이전 속도 사이의 가중치 차이를 더한 값이 있습니다. Nesterov momentum은 현재 veclocity과 이전 velocity에 대한 error-correcting term의 한 종류이다.
- 오류 수정 모델(error-correcting term)은 기본 변수가 공동 적분이라고도하는 장기 공통 확률 추세를 갖는 데이터에 가장 일반적으로 사용되는 여러 시계열 모델의 범주에 속합니다.
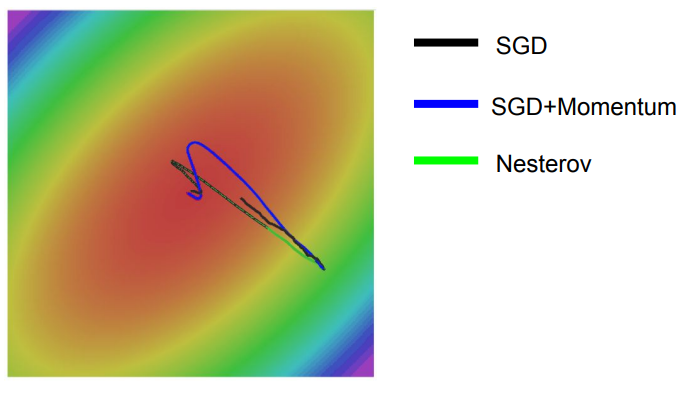
Nesterov나 SGD+Momentum이 SGD에 비해 속도의 방향으로 나아가기 때문에 훨씬 빠르다.
AdaGrad

velocity 대신 gradient의 제곱(sqaured_term)을 사용하고, update를 할 때 gradient의 제곱 식을 이용하여 나눠주게 된다.

Q1: What happens with AdaGrad?
A1: high condition number 문제는 한쪽은 매우 큰 gradient를 가지고 있고, 한쪽은 매우 작은 gradient를 가지고 있을 때, 작은 gradient는 작은 값으로 나누어 속도를 빠르게 하고, 큰 gradient는 큰 값으로 나누어 속도를 느리게 한다.
Q2: What happens to the step size over long time?
A2: 시간이 지남에 따라 제곱 기울기의 이 추정치를 계속 업데이트하기 때문에 실제로 단계가 점점 더 작아집니다. 따라서 이 추정치는 훈련 과정에서 단조롭게 증가한다. 이제 이로 인해 시간이 지남에 따라 단계 크기가 점점 작아집니다.
RMSProp
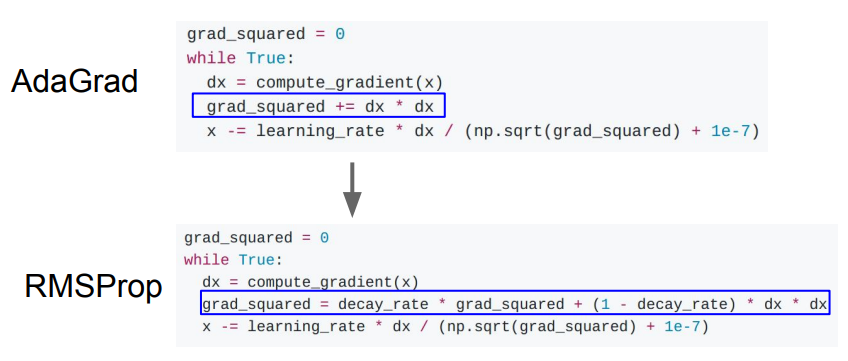
AdaGrad와 다르게 RMSProp는 gradient squared를 계속해서 가속하는 것이 아니라 decay해준다.
RMSProp에서는 gradient값이 leak하기 때문에, 원하지 않는 경우에도 속도를 늦추는 문제가 발생한다.
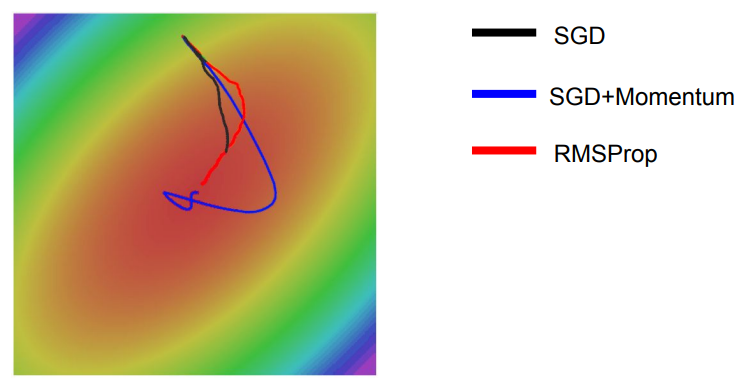
SGD+Momentum의 경우 Overshooting한 후 최적점을 향해 돌아오는 반면에, RMSProp은 속도는 조금 느리지만 최적의 경로만으로 진행한다.
Adam

like Momentum : weighted sum of gradient
like AdaGrad / RMSProp : moving estimate of our squared gradients
step을 update할 때, first moment(velocity)와 second moment(squared gradient)를 둘다 사용한다.
Q : What happens at first step?
A: Initialization을 한 후 첫 first moment를 계산했을 때, 여전히 second moment는 0의 값을 가지고, 첫 update 가 모두 끝나고 난 후에도 여전히 second moment는 0에 가까운 값을 가지게 된다. 이 값들을 이용해 첫 step을 가게 되면 0에 가까운 값으로 나눠주게 되어 엄청나게 큰 step을 가게 된다. 이러한 문제를 해결하기 위해 실제 Adam에서는 Bias term이 존재한다.
* 모든 식에 1e-7을 더한 값으로 나눠주는 이유는 0으로 나누는 일이 생기지 않도록 작은 값을 항상 더해주는 것이다.
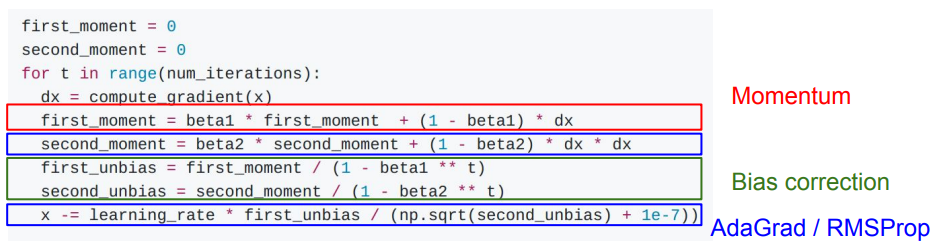
first, second moment를 구하고 난 후 first, second unbias를 구하는 term이 있다.
Adam with beta1 = 0.9, beta2 = 0.999, and learning_rate = 1e-3 or 5e-4 is a great starting point for many models!
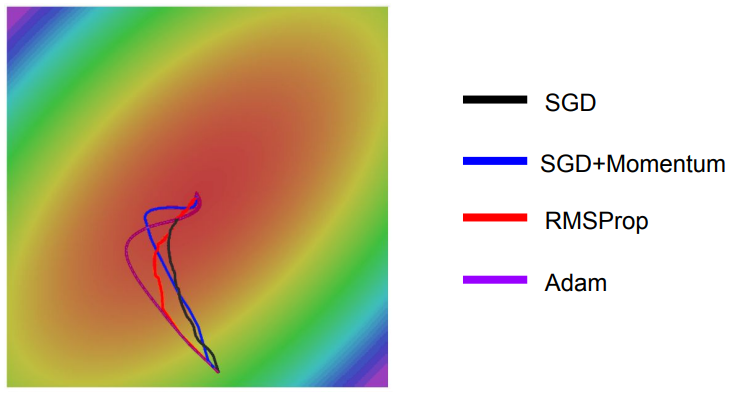
Adam은 Overshooting을 최소화하고, RMSProp와 같이 일정하게 진행하려 한다.
All Optimizer는 Learning rate를 Hyperparameter로 가진다.
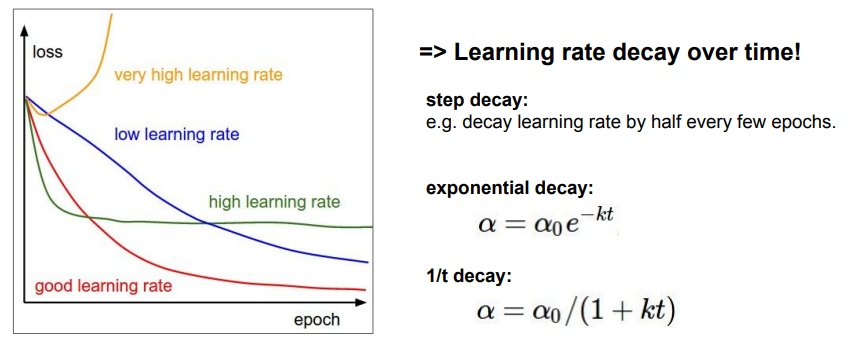
Q. Which one of these learning rates is best to use?
시작은 큰 lr값을 줘서 빠르게 진행하고, 이를 시간이 지날수록 decay 시켜서 지속적으로 작아지게 만든다.
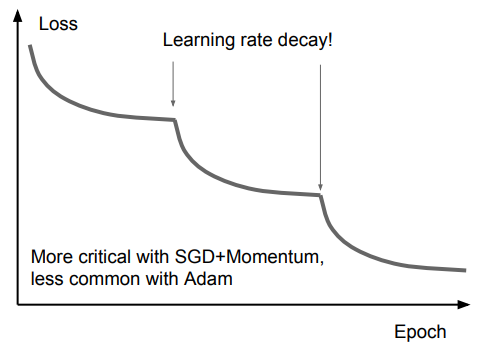
특정 lr로 학습을 진행하면서 Loss의 감소가 flatten 해질 경우, Learning rate decay(Second-order Optimization)를 통해 loss를 다시 감소할 수 있도록 해준다.
First-Order Optimization
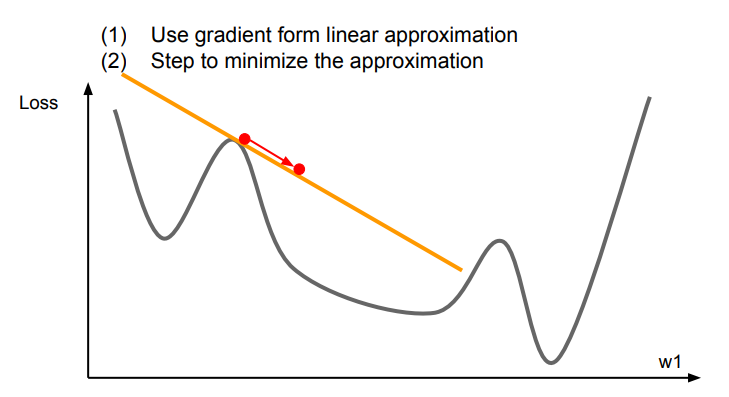
1차 미분을 이용하여 선형 근사를 통한 gradient를 이용한다.
Second-Order Optimization
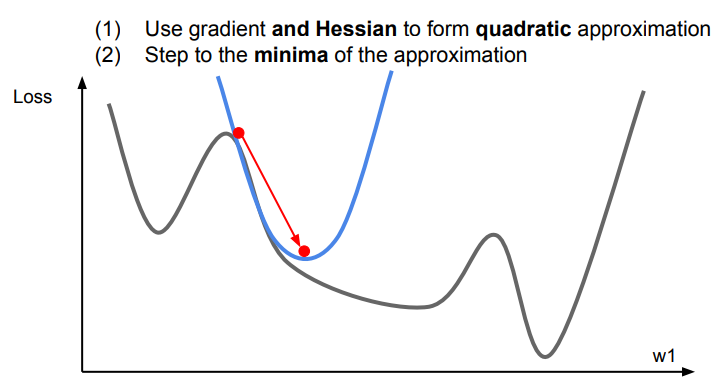
2차 함수로의 금사를 이용하여 이차함수의 minima를 향해 step한다.

각 step에서 2차함수의 minima를 향해 가기 때문에 learning rate가 필요하지 않다. 그러나 실제로는 quadratic 방법이 정확하기 않을 수도 있고, 단순히 minumum을 향해 나아가기를 원할수도 있기 때문에 사용을 많이 한다. 그래서 이 방법 대신에 Quasi-Newton method를 주로 사용한다.

L-BFGS
particular second-order optimizer
딥러닝에서는 잘 사용하지는 않는데, full-batch에는 효과적으로 작용하나, Stochastic case에서는 잘 작동하지 않는다. 또한 non-convex problem에도 잘 작동하지 않는다.
less stochastic을 가지는 style transfer 등에서 주로 사용한다.
In practice
- Adam is a good default choice
- full batch를 사용할 경우 L-BFGS도 좋은 선택이 될 수 있다.
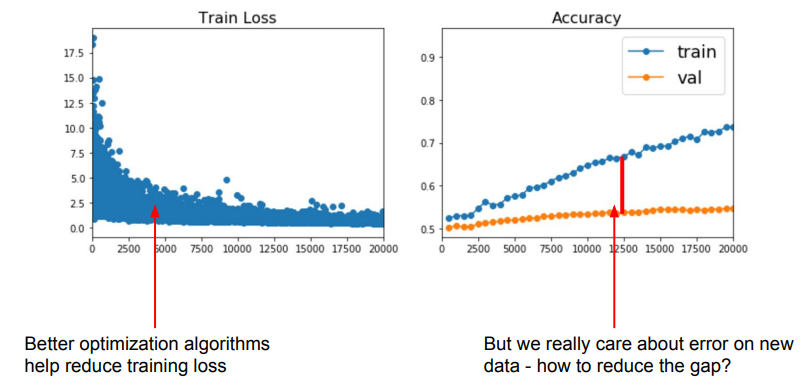
학습 과정에서 우리가 가장 중요하게 신경써야 할 부분은 학습에 사용하지 않는 validation data에 대한 error이다.
Model Ensemble
1. Train multiple independent models
2. At test time average their results
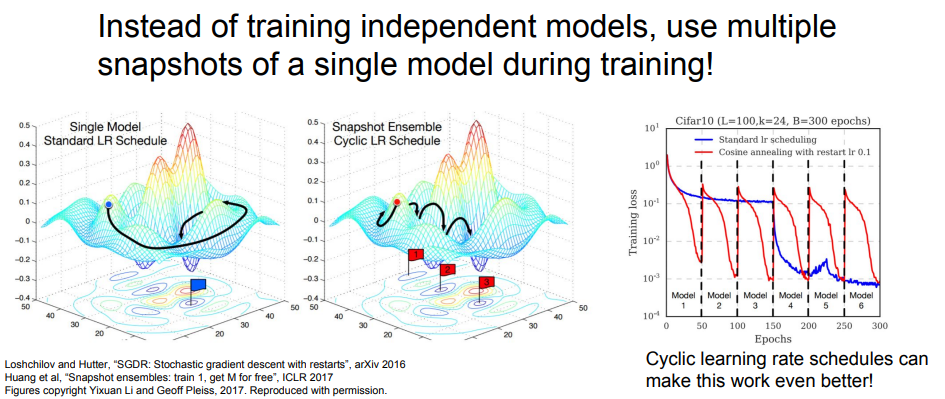
Tips and Tricks
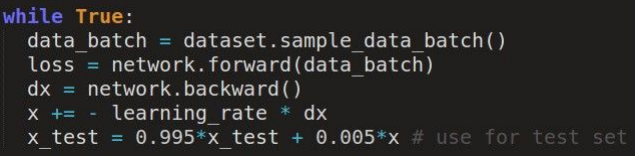
실제 parameter vector를 사용하는 대신, 파라미터의 이동평균값을 keep하고 test time에 사용한다. (Polyak averaging)
- 최적화 알고리즘이 매개변수 공간을 거쳐 간 자취(궤적)에 있는 여러 점의 평균을 구함.
- 최적화 알고리즘이 계곡 바닥 근처에 있는 점에 전혀 도달하지 못하면서 계곡의 양쪽을 여러 번 왕복하기만 하는 상황이 벌어질 수도 있는데, 계곡 양쪽의 모든 점을 평균화하면 바닥과 가까워진다 비블록(non-convex) 문제에서는 먼 과거에 거쳐 간 매개변수 공간 점들을 포함시키는 것이 좋지 않아 이동 평균을 사용
Single 모델을 사용할 때 성능을 올릴 수 있는 방법으로는 Regularization이 있다.
Regularization
1. Add term to loss
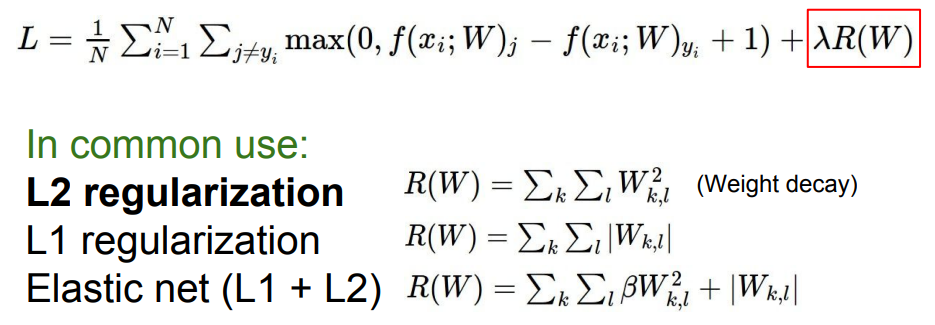
L2 regularization은 neural network에서는 많은 의미를 가지지 못하기 때문에 neural network에서는 다른 방식을 사용한다.
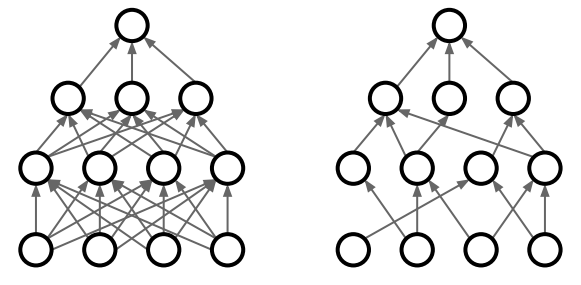
2. Dropout
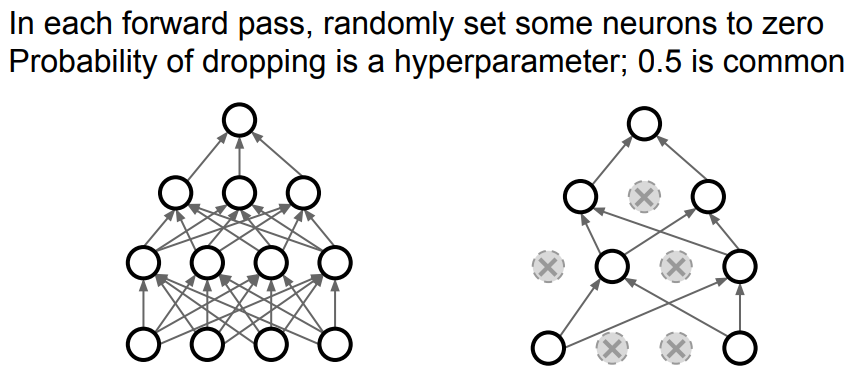
activation 값을 0으로 만들어 다음 layer로 전달되는 값이 없도록 만드는 방법


dropout은 feature간의 co-adaptation을 방지해준다.
- co-adaptation : 어떤 뉴런이 다른 특정 뉴런에 의존적으로 변하는 것
또한 single model에서 ensemble하는 효과가 있다. dropout을 할 때마다 새로운 subnetwork가 만들어지게 되고, 모든 dropout이 가능한 마스크에서 다 다른 potential subnetwork를 만들게 된다. dropout은 같은 시간동안 같은 파라미터를 공유하는 앙상블이 된다.

z는 random한 값을 나타내는데, test 상황에서 dropout을 하는것은 좋지 못하다.

dropout을 0.5로 둔 경우 test time의 a값은 학습시의 a값에 비해 1/2이 작은 값이 나왔다. 이를 간단하게 생각해보면, test time에는 dropout 비율을 곱해주면 된다.



3. A common pattern
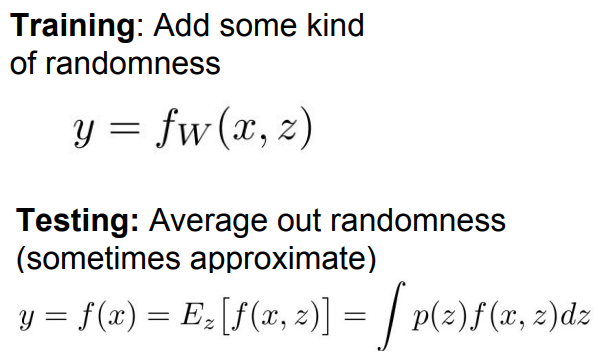
Training : Prevent Overfitting
Testing : Improve our Generalization
Ex. BatchNormalization
- Training : Normalize using stats from random minibatches
- Testing : Use fixed stats to normalize
Dropout 없이 BN만을 사용하여도 충분히 좋은 결과가 나오기도 한다.
4. Data Augmentation
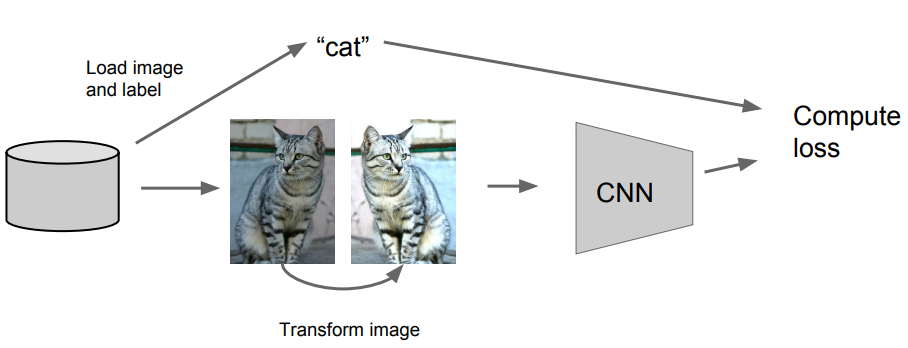
random transformed된 이미지를 이용하여 학습을 돌린다.
Horizontal Flips

Random crops and scales

Color Jitter



Max Pooling 하는 영역을 위 사진과 같이 랜덤하게 진행한다. test 시에는 stochasticity out의 평균값을 구해서 진행한다.
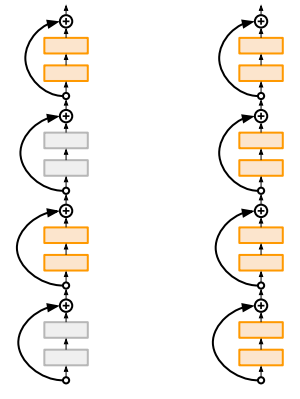
학습중에 일부 layer를 drop한다. test시에는 전부다 사용
dropout과 다른점은 dropout은 각 layer에서 p만큼을 drop하고, Stochastic Depth는 일부 layer를 drop한다.
Transfer Learning with CNNs
CNN을 학습하기 위해 많은 데이터가 없는 경우 Transfer Learning을 활용할 수 있다.
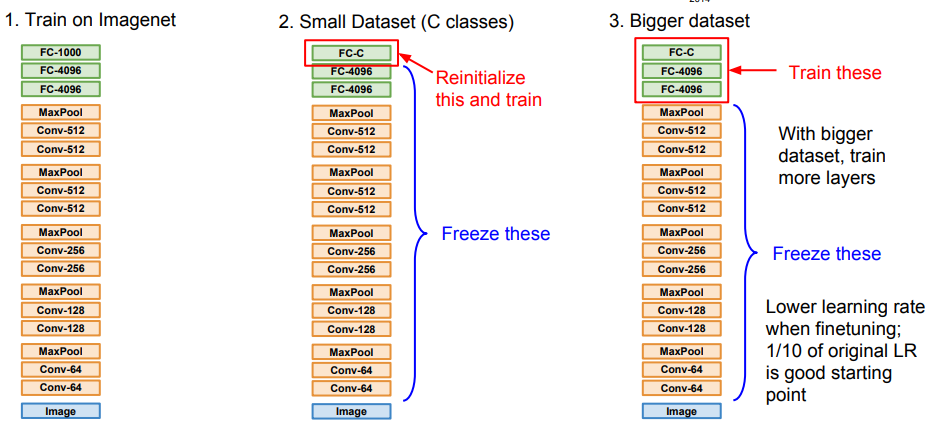
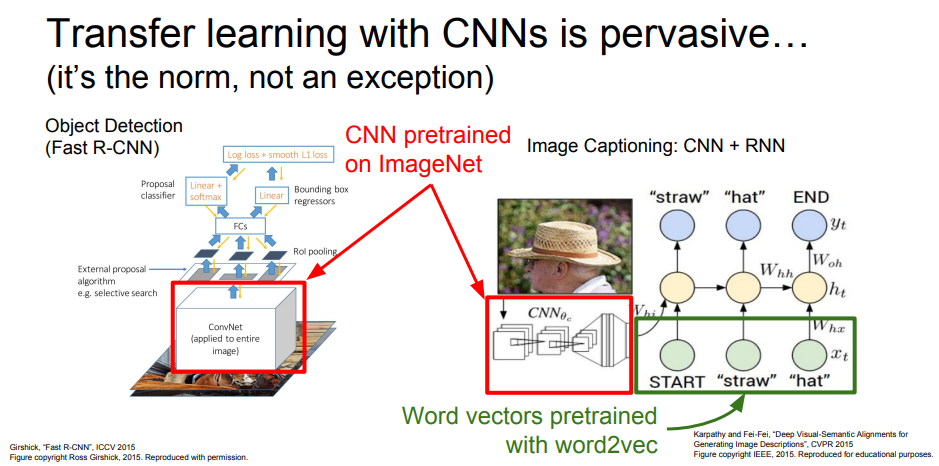
Object Detection이나 Image Captioning에서 둘다 CNN구조를 활용하는데 최근에는 이 부분은 직접 학습하지 않고 ImageNet으로 pretrained된 CNN을 사용한다.
Object Detection에서는 일부 layer만 재학습시키고, Image Cationing에서는 pretrain된 CNN과 거대한 Text corpus로 pretrain된 word vector를 사용하고, 전체를 사용하는 데이터셋에 맞게 재학습시킨다.
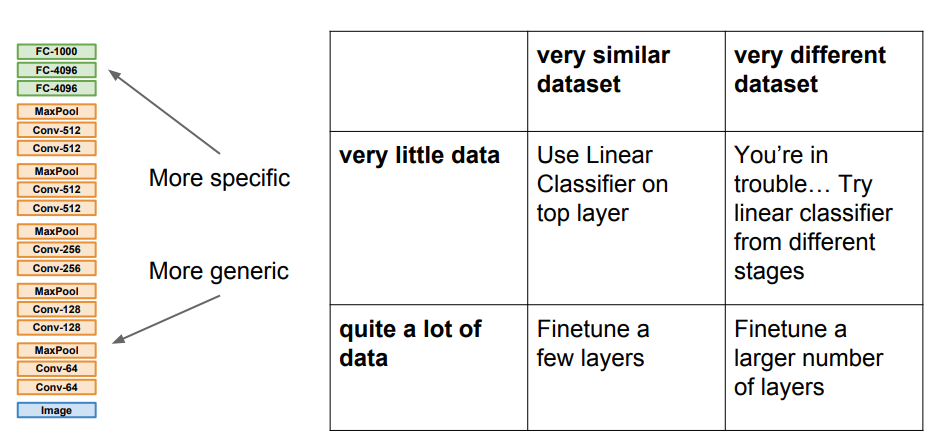
Takeaway for your projects and beyond
Have some dataset of interest but it has < ~1M images?
- Find a very large dataset that has similar data, train a big ConvNet there
- Transfer learn to your dataset
출처: http://cs231n.stanford.edu/2017/index.html
https://en.wikipedia.org/wiki/Error_correction_model
https://www.slideshare.net/KyeongUkJang/chapter-8-optimization-for-training-deep-models
'Study > CS231n' 카테고리의 다른 글
| Lecture 6. Training Neural Networks I (0) | 2022.02.07 |
|---|---|
| Lecture 5. Convolutional Neural Networks (0) | 2022.01.21 |
| Lecture 4. Introduction to Neural Networks (0) | 2022.01.13 |
| Lecture 3. Loss Functions and Optimization (0) | 2022.01.11 |
| Lecture2. Image Classification (0) | 2022.01.10 |




댓글